


Why Postgres should be the last database you'll ever need
Postgres: The One-Stop Data Party


Being a sucker for reading unnecessary books in fields I have no experience in got me into flipping through the Google Site Reliability Engineering book, where I had read the most elegant concept that seems obvious at first but isn't applied in the real world very often. It read
Simple software breaks less often and is easier and faster to fix when it does break
- Google's Site Reliability Engineering Book
Thinking about this concept and how companies leverage a vast number of technologies to build their data-driven infrastructure, and with my limited experience using the best SQL-based database platform, I got the gears turning in my head. In a world where everyone uses Redis as an in-memory Cache, where Apache Kafka is the defacto real-time message queue, and where time series data has its own database, it seems a bit redundant because, in this limited example, we still need to be experts in all three. In this article, given the acid-compliant nature of Postgres, I'll focus on replacing all three problems with simple Postgres-based tables.
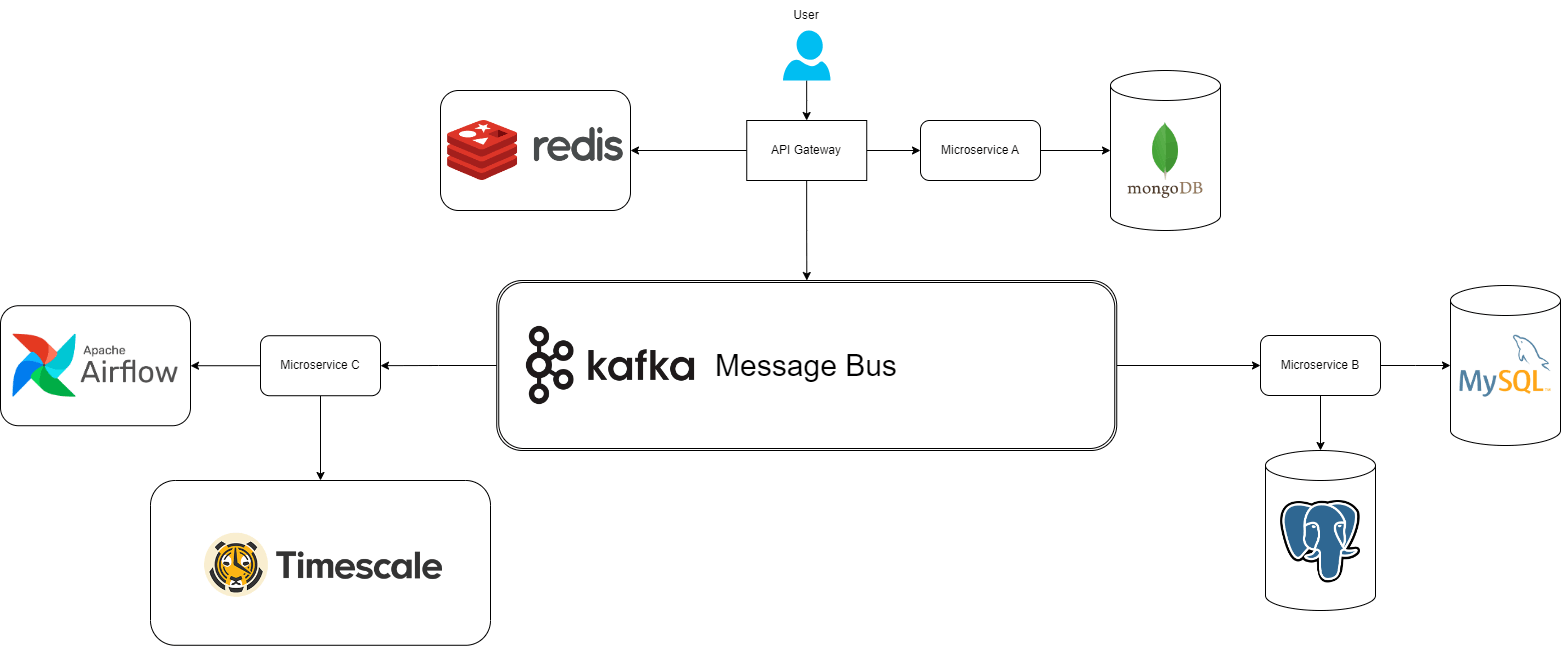
Terminating Timescale
Replacing Timescale, the time-series database, with PostgreSQL involves leveraging the powerful features of PostgreSQL to handle time-series data efficiently. In PostgreSQL, the table layout is crucial in achieving optimal performance. Instead of relying on Timescale's hypertables, specialized tables for time-series data, you can create a regular PostgreSQL table with a timestamp column. Indexing this timestamp column is essential for quick data retrieval.
-- Step 1: Creating a Table
CREATE TABLE time_series_data (
id SERIAL PRIMARY KEY,
event_timestamp TIMESTAMPTZ NOT NULL,
data_value DOUBLE PRECISION NOT NULL,
-- Add other necessary columns as per your data requirements
);
-- Step 2: Indexing on Time Stamp
CREATE INDEX idx_event_timestamp ON time_series_data (event_timestamp);
To maintain the advantages of partitioning in Timescale, you can use PostgreSQL's table partitioning feature. This involves creating child tables inherited from a master table, each handling a specific time range. Proper indexing on these child tables ensures that queries for a particular period are executed swiftly.
-- Step 3: Partition the master table
CREATE TABLE time_series_data_2023 PARTITION OF time_series_data
FOR VALUES FROM ('2023-01-01') TO ('2024-01-01');
Similarly, you might want to alter your configuration settings to better align with how Timescale operates. This might mean changing some of the default options given below:
Shared Buffer: 25% to 30% of available memory
Effective Cache Size: 50% to 75% of available memory
Working Memory: Adjust based on the complexity of queries and available memory
Maintenance Working Memory: Sufficient for maintenance operations like index creation
Write Ahead Log: Set to replica or logical for better performance
Maximum and Minimum WaL Value: Adjust based on the write intensity and available disk space.
Checkpoint Completion Target: Aim to balance write performance and checkpoint duration.
Auto Vacuum: Enable and configure autovacuum settings for automatic maintenance.
You can alter these via the following generic DML command
ALTER SYSTEM SET shared_buffers = '2GB';
Killing Kafka with a Message Queue
A queue in its most basic essence is JUST A QUEUE, a data structure that follows the FIFO (First-in, First-Out) rule. That means that new data is added to the tail of the queue, and data is read from the head. So, a straightforward implementation will only deal with enqueuing messages to the tail and dequeuing from the head. The table would have the following schema:
-- Step 1: Create the Schema
CREATE TABLE queue_table (
id UUID PRIMARY KEY,
inserted_at TIMESTAMP NOT NULL DEFAULT NOW(),
message_payload BLOB
);
-- Step 2: Index the inserted_at column on its sorted values
CREATE INDEX inserted_at_idx
ON queue_table (inserted_at ASC);
Now, to insert the data into the queue is as simple as inserting data into the table, and to receive and delete, we can delete the data and return them.
-- Adding to Queue
INSERT INTO queue_table (id, inserted_at, message_payload)
VALUES (gen_random_uuid(), NOW(), RAWTOHEX('top secret information'));
-- Returning the Data
DELETE FROM queue_table qt
WHERE qt.id =
(SELECT qt_inner.id
FROM queue_table qt_inner
ORDER BY qt_inner.inserted_at ASC
FOR UPDATE SKIP LOCKED
LIMIT 1)
RETURNING qt.id, qt.inserted_at, qt.message_payload;
Although not the most optimal, it can still comfortably do a few thousand transactions per second.
Redundant Redis
In PostgreSQL, you can create a cache table with columns such as key and corresponding value pair to store the cached data. We will also require a timestamp to tell when the content was added. Indexing the key column ensures fast retrieval of cached values. To emulate Redis's in-memory performance, consider adjusting PostgreSQL's configuration settings. Increase shared_buffers to allocate more memory for caching and adjust effective_cache_size accordingly. Additionally, configure work_mem to optimize memory usage during query execution. While PostgreSQL may not match Redis in pure in-memory caching speed, its versatility and integration capabilities make it a compelling alternative. Implementing
this in Postgres would involve the following table creation and modification commands.
-- Step 1: Create table to cache results
CREATE TABLE redis_type_cache (
_key TEXT NOT NULL,
_value TEXT NOT NULL,
inserted_at TIMESTAMP NOT NULL DEFAULT NOW()
);
-- Step 2: Create an index on _KEY
CREATE INDEX redis_type_cache_key ON redis_type_cache USING HASH (_key);
Note that this will keep writing to the cache infinitely, which will hog all your memory. To solve this, we can use a corn job to remove old records by following the steps given below:
CREATE OR REPLACE FUNCTION delete_old_rows()
RETURNS VOID AS $$
BEGIN
DELETE FROM redis_type_cache
WHERE inserted_at < NOW() - INTERVAL '36 hours';
END;
$$ LANGUAGE plpgsql;
PG_HOST="your_host"
PG_DATABASE="your_database"
PG_USER="your_user"
PG_PASSWORD="your_password" # Consider using a more secure method for password handling
psql -h $PG_HOST -d $PG_DATABASE -U $PG_USER -c "SELECT delete_old_rows();" -W $PG_PASSWORD
# save file as delete_row.sh
> chmod +x delete_old_rows.sh # make the file executable
> crontab -e
# add the following to crontab so that the file runs everyday at 6pm
0 18 * * * delete_row.sh
Conclusion
In conclusion, the idea of simplifying data infrastructure by leveraging the power of a versatile and reliable database like PostgreSQL is compelling. By replacing specialized tools like Timescale, Kafka, and Redis with well-designed PostgreSQL tables, you can achieve simplicity, robustness, and ease of maintenance.
For time-series data, the approach involves creating regular PostgreSQL tables with proper indexing and partitioning for efficient data retrieval. In the realm of message queues, a basic FIFO queue can be implemented using a simple table structure. This approach eliminates the need for Apache Kafka, offering a straightforward and efficient way to handle message queuing directly within PostgreSQL. Even for in-memory caching, PostgreSQL can serve as a capable alternative to Redis. By creating a cache table with appropriate indexing and periodic cleanup processes, you can achieve caching functionality within the same database that handles other aspects of your data.
The key takeaway is that simplicity often leads to reliability. A consolidated approach using PostgreSQL not only simplifies the technology stack but also makes it easier to manage and maintain the entire data infrastructure. That being said, there can be no true alternatives to the dependencies mentioned in the article, because of their accepted use in corportations, but it was fun thinking that in an alternative universe, everything could just be Postgres. No doubt, if you need to scale your infrastructure to the level of Google or Microsoft, where you deal in petabytes of data each week, these expert technologies are optimised for results, but if you are just starting our or creating a hobby project, a simple Postgres Database isn't all that bad.